We are currently witnessing a huge growth in data volumes and number of connected devices. Demanding of big data processing is extremely growing in enterprise domain, medical research, large scale scientific research etc. The term Big Data has gone through from very simple concept to more complicated in these days. Historically, the data was mainly being produced from workers. In other words, the companies will have to manually enter data into computer systems. After the evolution of the Internet, users and machines are started to accumulate data. So, data is generated at such a higher rate that it is impossible to store, transfer and analyze it with limited computing power, storage and bandwidth.
Advancement in the field of Distributed Systems allows researchers to store data in a distributed manner over multiple machines and networks empowered by programming models that have been developed to process data efficiently over such distributed storage. When we say Big Data, people often think about Hadoop echo system and assume anything can be achieved using Hadoop system which is not the case. There are lots external tools were built on top of Hadoop for different use cases like batch data processing, real-time processing, streaming data processing etc. Out of this tools and technique, MySQL NDB cluster provides fabulous features in terms of data storage and streaming. The purpose of this article is provides more insight of MySQL NDB cluster and streaming events through cluster, so that developers can integrate or implement the solutions on top of NDB cluster.
MySQL NDB cluster
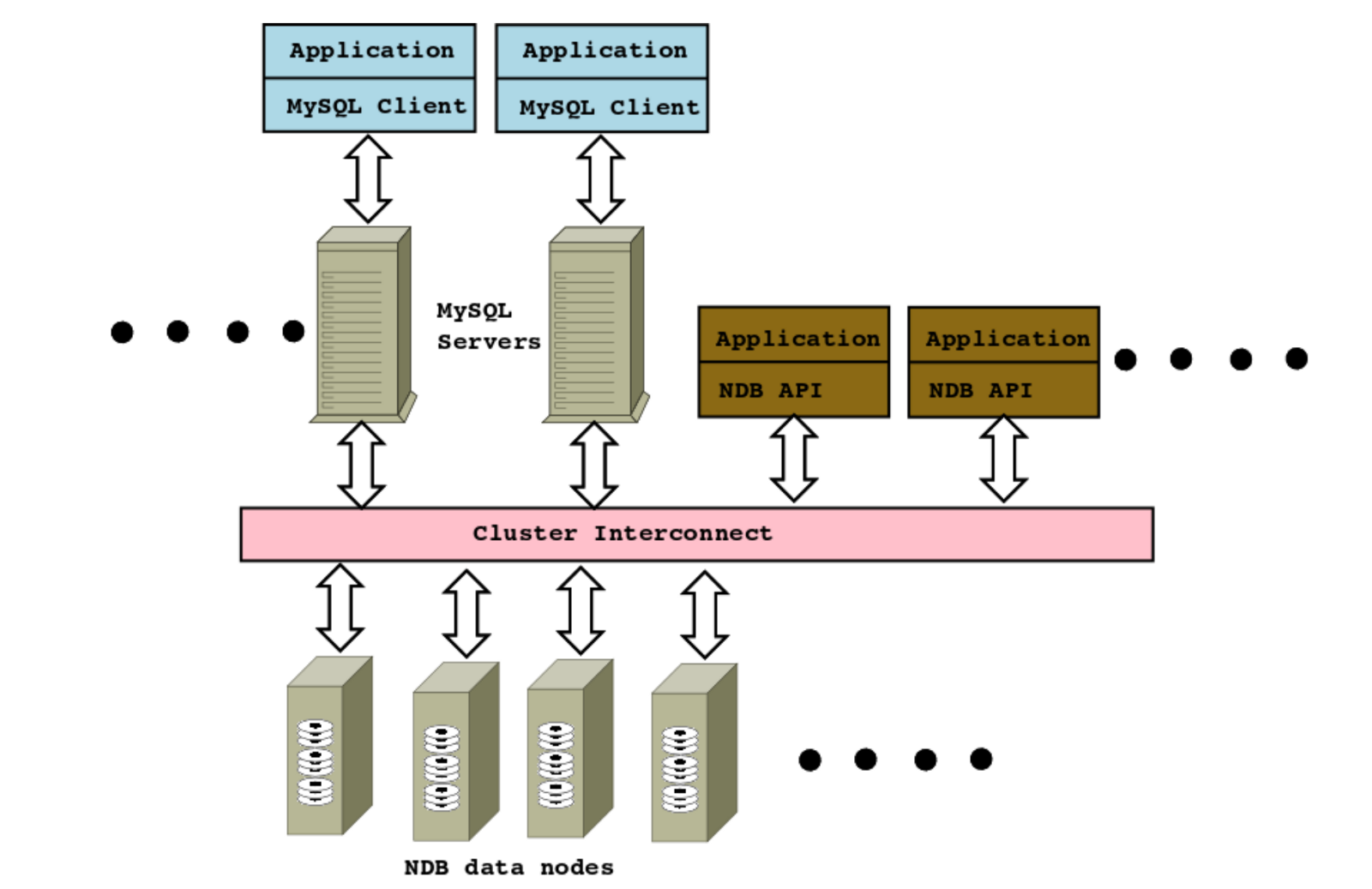
MySQL Cluster comprises three types of node which collectively provide service to the application; Data nodes, Application nodes, Management node. The MySQL cluster’s real-time design provides negligible latency response with the power to service millions of operations per second. It also provides load balancing and the ability to add more nodes in to a running cluster with zero downtime which allows linear database scalability to handle peek workloads. The MySQL Cluster provides both SQL and native NoSQL APIs for data access and manipulation. Hops-YARN mostly uses the NoSQL APIs because it allows us to reach a high throughput by bypassing the MySQL Server and directly communicate with the storage layer.
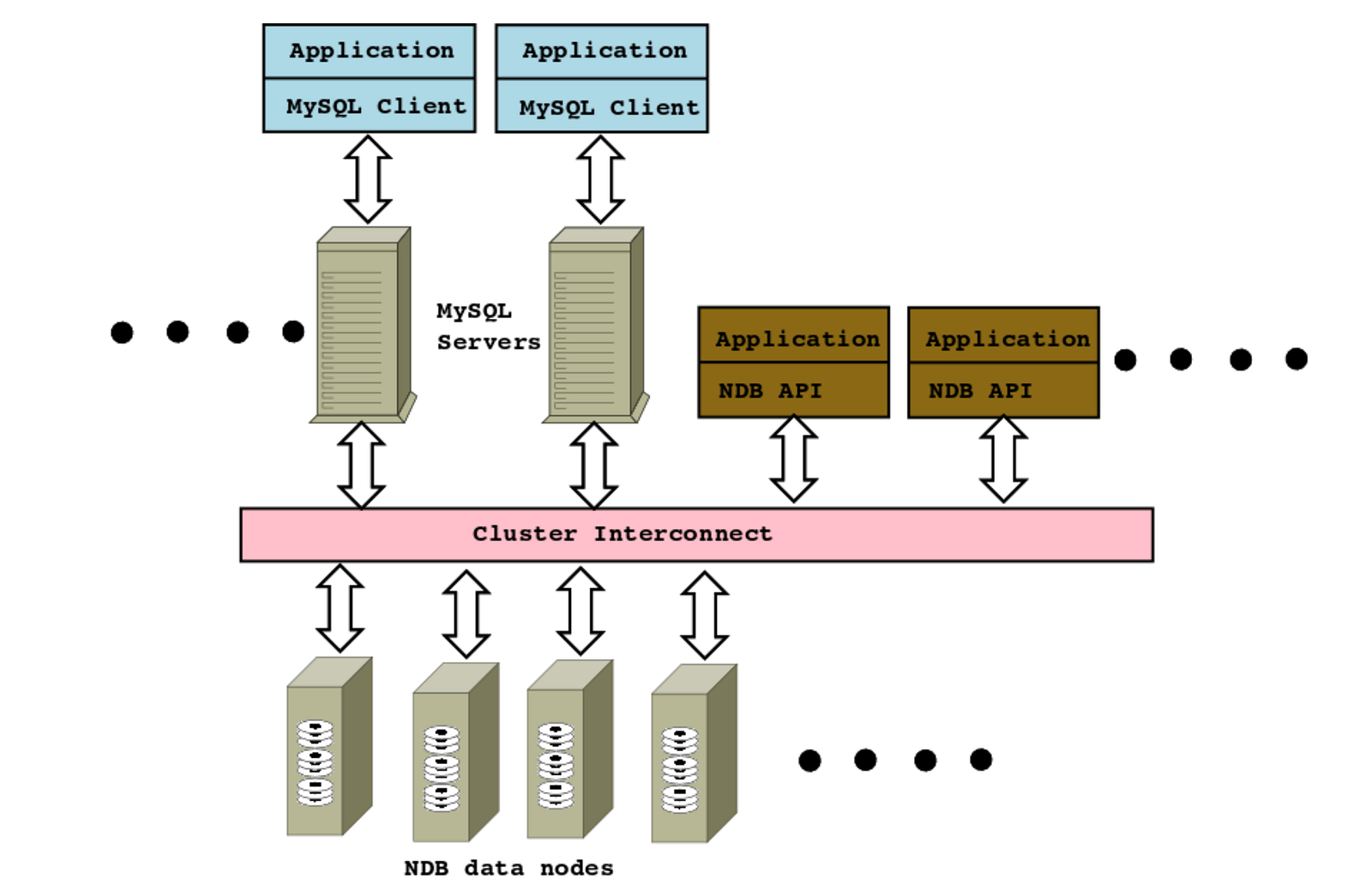
MySQL NDB cluster with nodes
Data nodes
The Data nodes manage the storage and access to data. Tables are automatically sharded across the data nodes which also transparently handle load balancing, replication, fail-over and self-healing. Data nodes are divided into node groups . The number of node groups is calculated as:
Number of Node Groups = Number of Data Nodes /Number of Replicas
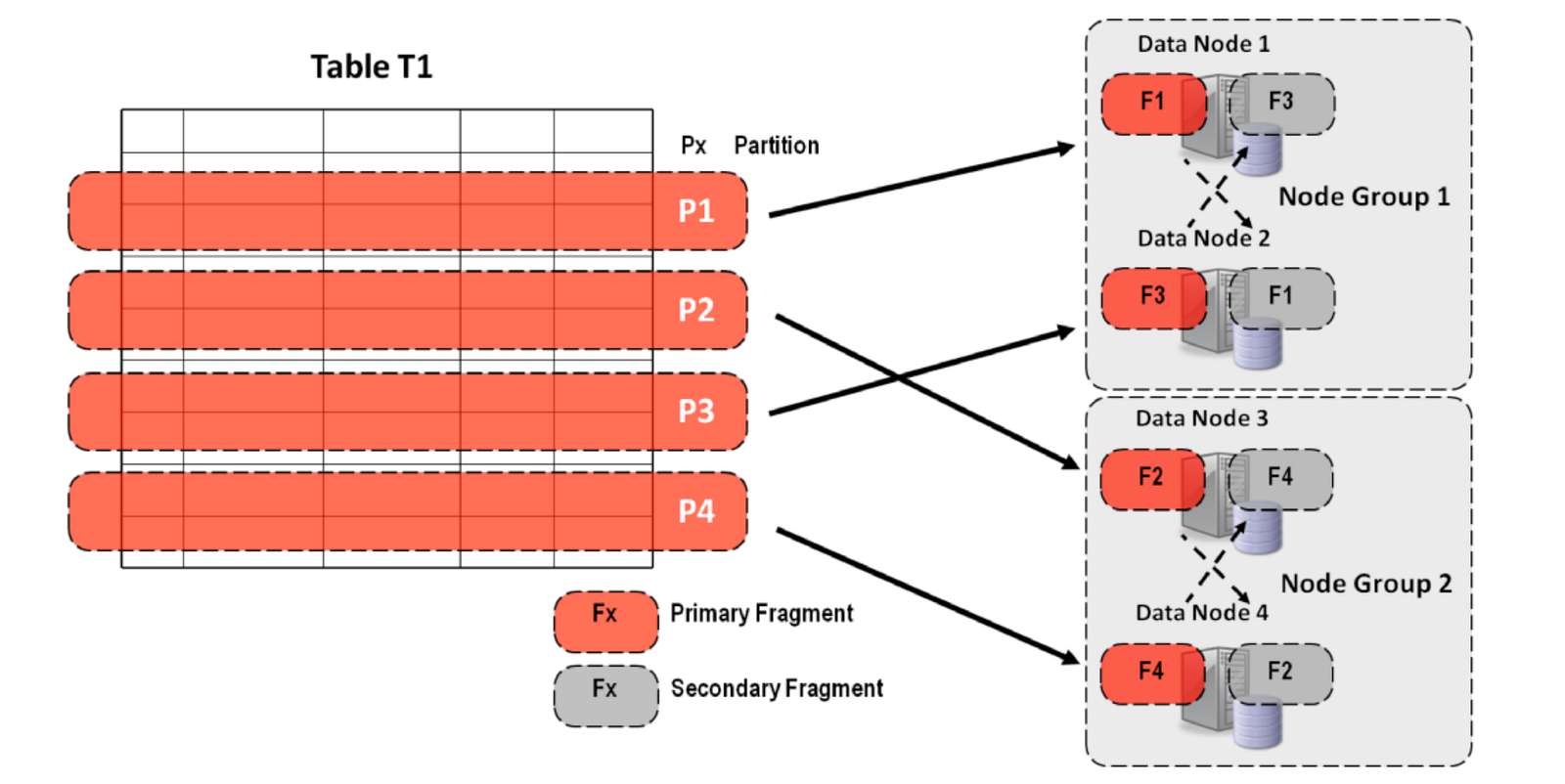
Nodes and Node groups
The partitions of data are replicated within the same node group. For example, suppose that we have a cluster consisted with 4 data nodes with replication factor of 2, so there are 2 node groups. All the rows for table are sliced into partitions and each data node keeping the primary fragment for one partition and backup fragment for another partition. Query from MySQL server needs lots of network hops to the data nodes or in between data nodes in order to fetch the required data which would affect performance and scalability will be slashed down. So, minimizing the number of network hops would yield best performance in MySQL cluster query lookup. By default, Sharding is based on hashing a table’s primary key, however the application level can include a sub-key for improving performance
by grouping data commonly accessed together in the same network partition, hence reducing network hops.
Application nodes
The Application nodes are allowing connectivity from the application logic to the data nodes. There are several well-known APIs are presented to the application. MySQL provides a standard SQL interface which provides connectivity to all of the leading web development languages and frameworks. MySQL cluster supports whole range of NoSQL interfaces including Memcached, REST/HTTP, C++ (NDB-API), Java and JPA. MySQL server internally uses the low level NDB API to access the data nodes. The performance gain will be increased by accessing the data nodes directly using the C++ NDB API
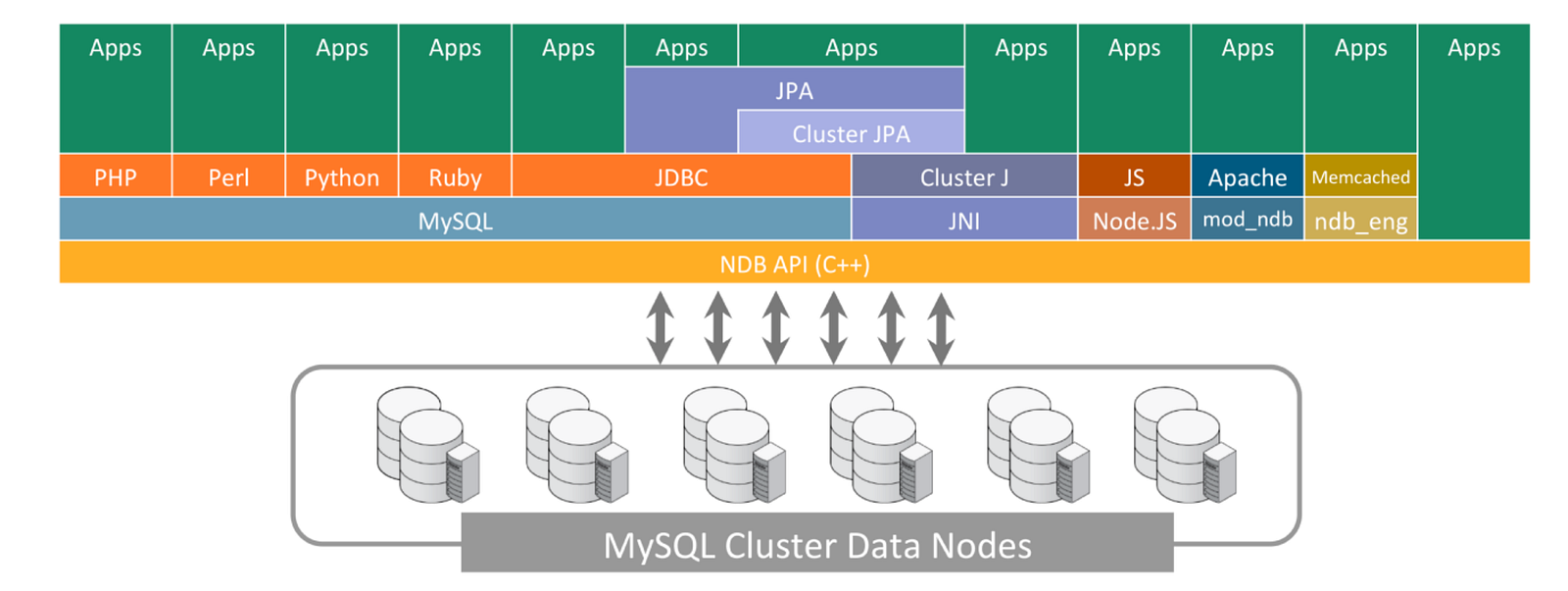
Diversity of application connectivity
Management nodes
The Management nodes are used to configure the cluster and provide arbitration in the event of network partitioning. It also provides rich functionalities to administrators to monitor the cluster usage. It also provides administrative services for the cluster. These include starting and stopping MySQL cluster nodes, handling MySQL cluster logging, backups, and restoration from backups, as well as various other management tasks.
MySQL NDB cluster event streaming
The rows of tables stored in different data-nodes in NDB are being updated by transactions which are handled by multiple internal transaction coordinators. Each transaction coordinator is starting, executing and committing transactions independently in different data nodes. Concurrent transactions only interact where they attempt to lock the same row. This design minimizes unnecessary cluster-wide synchronization which is required by transaction coordinators to obtain consistent point in time to commit transactions. This enables linear scalability of reads and writes in NDB cluster.
The stream of changes made to rows stored at a different data node is written to a local Redo log for node and system recovery. The change stream is also published to NDB API event listeners, including MySQLD servers recording Binlogs which then will be used for cluster replication. Each data-node’s stream comprises the row changes it was involved in, as committed by multiple transactions, interleaved in a partial order which cannot be used to create meaningful transaction object. This is because of all changes by transaction are not reflected in a single data-node’s stream.
The disseminated stream from each data node is called event streams as trans actions are fundamentally update/delete/insert events on the database. These row event streams are generated independently by each data node in a cluster, but to be useful they need to be correlated together. During a system-wide crash recovery, all the data nodes need to recover to cluster-wide consistent state which contains only whole transactions existed at some point in time. One possible way to do is an analysis of the transaction ids and row dependencies of all recorded row modifications to find a valid order for the unified event streams. This process would add an extra overhead and non-deterministic time of recovery. NDB cluster uses a distributed logical clock known as the epoch to group large sets of committed transactions together to slash down this problem. The epoch atomically increases every 100 milliseconds by default and it can be represented by 64 bit number. So, each 100 milliseconds, a Global Commit Protocol which is known as distributed consensus protocol results in all transaction coordinators in the cluster mutually agreeing on a single point of time at which to change epoch. The following images shows an example of epoch counter and corresponding event streams caused by several transactions. Epoch boundary has been defined by cluster-wide consistent point in time; the difference between commit of the first transaction in epoch n+1 and commit of the last transaction in epoch n.
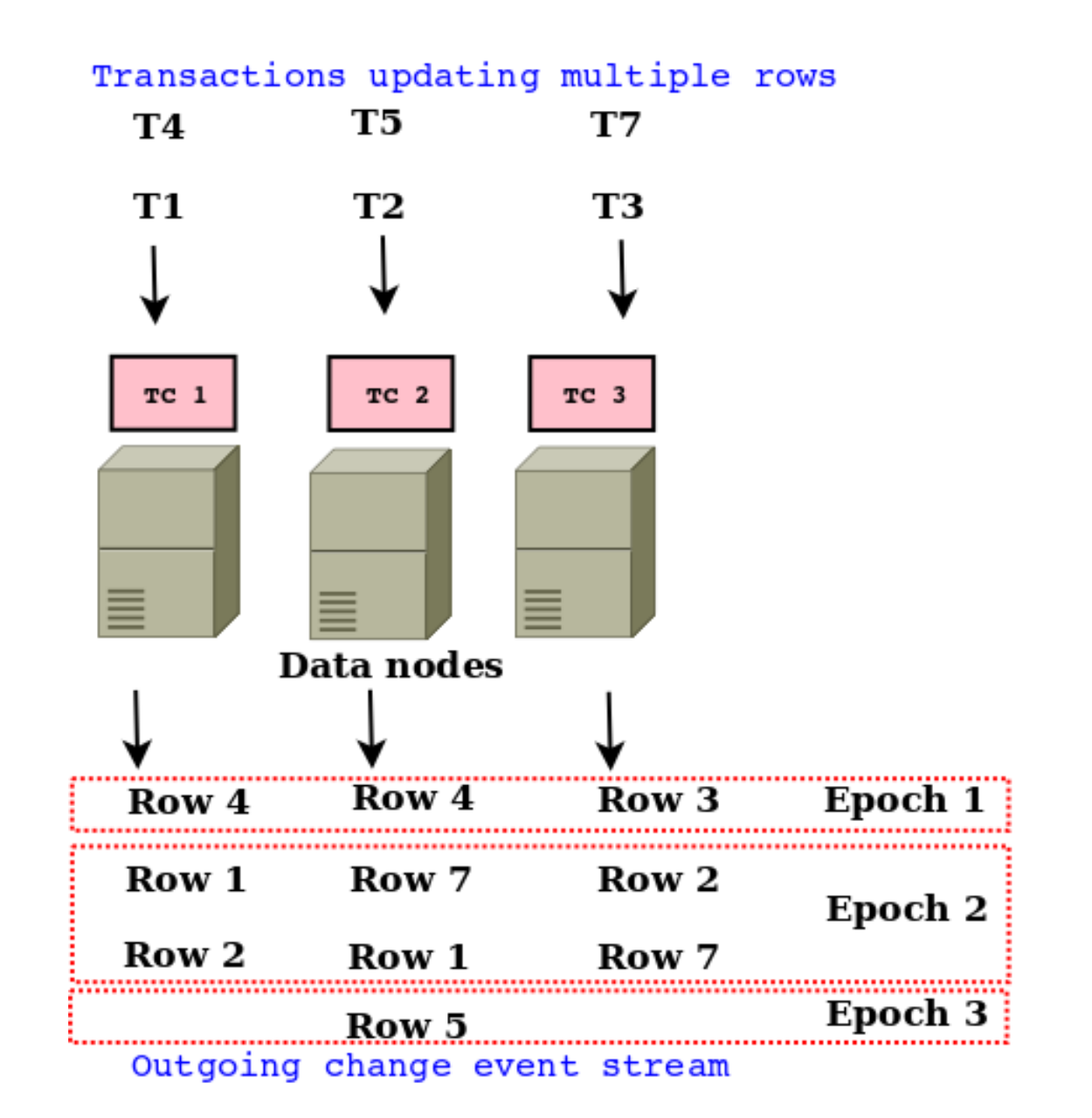
Transactions at different data nodes and possible event streaming
The fundamental property of epoch is that, each epoch carries zero or more committed transactions and every committed transaction belongs to one epoch. This property was mainly used to build our Event Streaming library discussed in following next sections. As we have discussed before, all the row event streams are produced independently by each individual data node in the cluster; it is impossible to use those individual events from the data nodes to create a meaningful transaction state. Once all this independent streams are combined and grouped by epoch number, meaningful unified stream could be constructed. As epochs give only a partial order, one of the interesting facts about transaction ordering is that, within an epoch, row changes may be interleaved in any way, except that multiple changes to the same row will be recorded in the order they were committed. This means that applications that are constructing these transactions related objects should use some special flag to order them. Other than that, intra epoch bounty transactions can be ordered as NDB API internally ordered the epoch in sorted manner. For instance, as shown in following figure , T4 − > T1(Happened before), and T7 − > T5. However, we cannot infer whether T4 − > T3 or T3 − > T4. In epoch 2, we see that the row events resulting from T1, T2 and T7 are interleaved. The following figure also shows the possible ordering of transactions in between epoch boundaries.
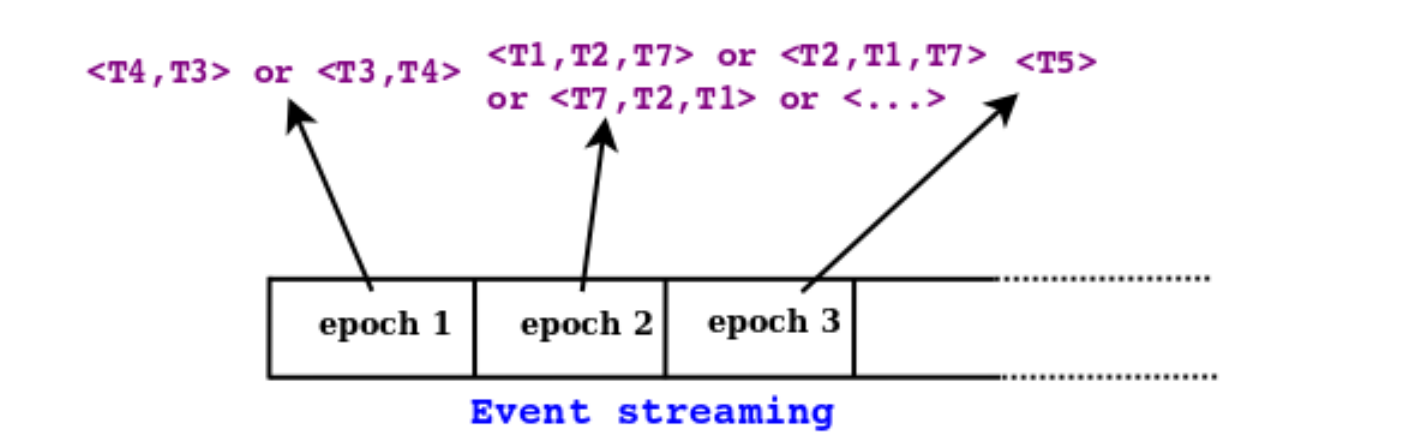
Merge events and ordering the transactions
If an application has a strict requirement of transaction ordering in a epoch interval, NDB API provides special function call setAnyValue which applications can pass any values (ex: atomic auto increment value) in NDB transaction operation. So, during an event processing, this value could fetch from streaming to order the transactions before delivered to the application. As mentioned before, the row changes in data nodes are recorded by MYSQLD process for replication. The following images represents non-cluster replication which master and slave servers are participating during the replication process.
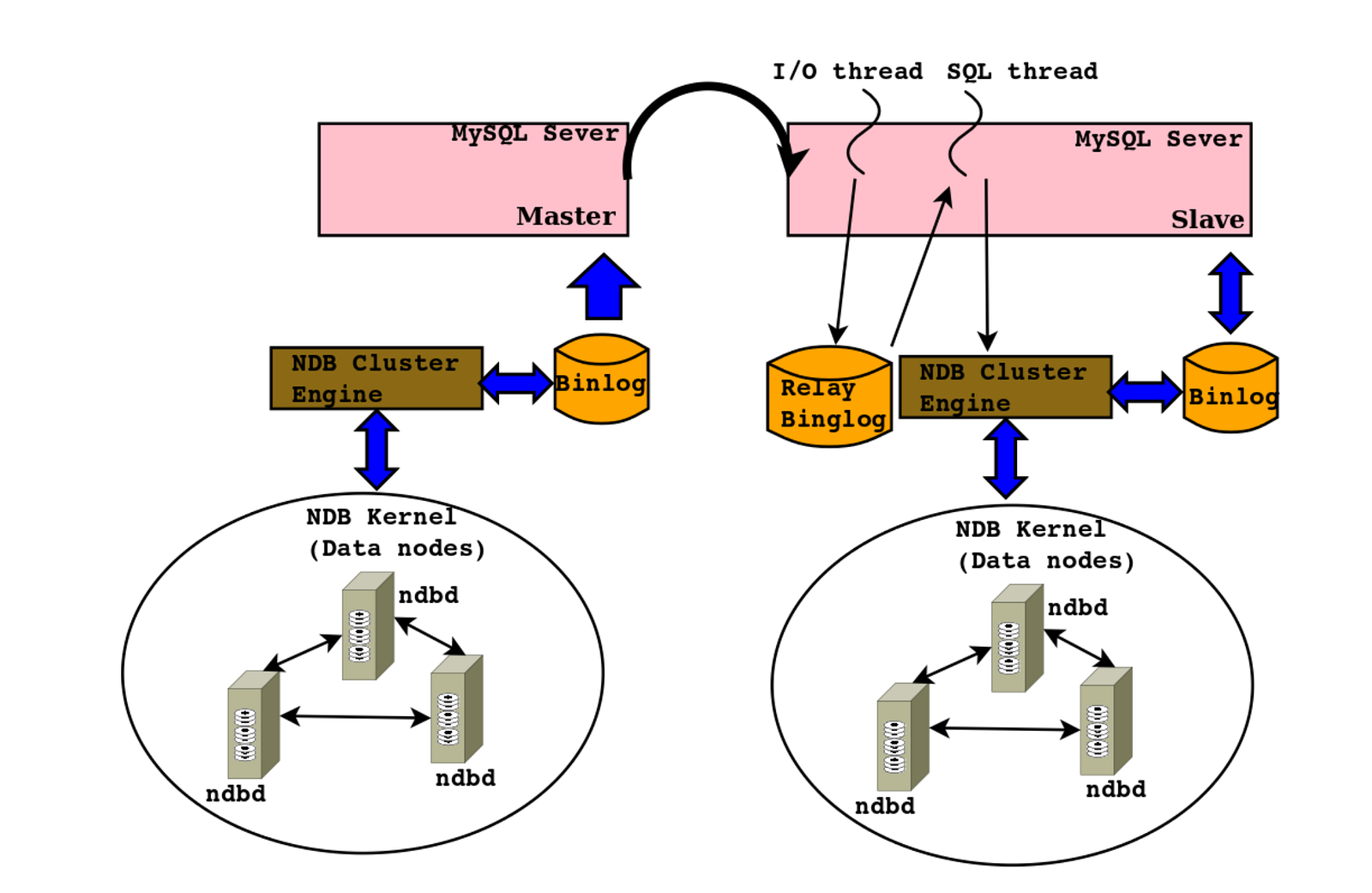
MySQL Cluster-to-Cluster Replication Layout
The MySQL supports other advanced type replication called multi master replication or circular replication where all the masters are replicating data among different cluster.Fundamentally MySQL replication process is asynchronous which means that replication process in the slave server can be started in a different time than the one taking place in master server. This would make replication more flexible and make sure that even if connection lost in between master and slave, replication will procees when the slave connection resumes. The master is being a root of the operations of data replication and the slave being the receiver of these. In this scenario, Master cluster’s MySQLD listens to the row change streams arriving from each data node, and merge-sorts them by epoch into a single, epoch-ordered stream. When all events for a given epoch have been received, NDB binary log injector thread which runs on MySQLD process records a single Binlog transaction containing all row events for that epoch. When slave sees any activity on binlog file, IO threads are copying those transactions to slave’s relay log file. It is then that SQL threads are started processing those transactions in a serial manner into slave database.
Conclusion
We have seen how MySQL NDB cluster structures the nodes to handle massive parallel transactions and streaming them if any subscription made to table. MySQL NDB cluster using epoch concept to define the transactions boundaries to execute transactions among data nodes to maintain the data consistency. Later, we have realized how events are dispatched and how we should order the events to get the completed transactions.
Application can use this concept to get the changing data from database to implement awesome logic such as
a. Without application thread looping for change, we can just subscribe for table and get the event