Pinterest Infrastructure engineers are the caretakers of more than 75 billion Pins–dynamic objects in an ever-growing database of people’s interests, ideas and intentions. A Pin is stored as a 1.2 KB JSON blob in sharded MySQL databases. A few years back, as we were growing quickly, we were running out of space on our sharded MySQL databases and had to make a change. One option was to scale up hardware (and our spend). The other option–which we chose–was using MySQL InnoDB page compression. This cost a bit of latency but saved disk space. However, we thought we could do better. As a result, we created a new form of MySQL compression which is now available to users of Percona MySQL Server 5.6.
JSON is efficient for developers, not machines
As a small start-up, Pinterest built and scaled its MySQL environment to tens of millions of Pinners without having an engineer who specialized in the care and feeding of MySQL. This was a testament to MySQL’s ease of use, but it also meant non-trivial changes were not practical. In particular, adding columns to MySQL tables was impossible without knowledge of specialized tools such as the online schema change scripts from Percona, GitHub, or (my favorite because I helped build it) Facebook.
Storing almost all Pin data in a JSON blob worked around the inability to add columns to MySQL tables. This flexibility came at the cost of storage efficiency. For example, we store a field called “uploaded_to_s3” as a boolean. If we had stored this as a boolean in MySQL, the field would have only used 1 byte. With the JSON representation below, we wrote 24 bytes to disk, largely as a result of the field name being stored in the JSON blob. About 20 percent of a Pin’s size comes from field names.
How the boolean uploaded_to_s3 is stored in JSON
, ‘"uploaded_to_s3": true
InnoDB page compression
As it’s normally configured, InnoDB “thinks” in 16KB pages and will attempt to compress a user-defined number of pages and push them into the space of a single page. (For a deep dive on how InnoDB page compression works, I suggest reading these fine docs.)
However, we found several significant downsides to InnoDB page compression:
- InnoDB’s buffer pool, its in-memory cache, stores both the compressed and uncompressed pages. This is helpful if data from a page is read repeatedly in relatively quick succession since the data doesn’t need to be decompressed multiple times, but it isn’t memory-efficient. In our case, we have a significant caching layer (managed by Mcrouter) in front of MySQL, so repeated reads are somewhat rare.
- The fundamental unit of work is still a 16KB page. This means that if a set of pages to be compressed don’t fit into 16KB or less, the compression fails and no savings are realized. It also means that if the table is configured for a compression ratio of 2:1, but the pages happen to compress extremely well (perhaps even all the way down to a single byte, for purposes of our thought experiment), the on-disk size is still 16KB. In other words, the compression ratio is effectively still only 2:1.
- In general, latency is higher for tables that use InnoDB compression, especially those under high concurrency workloads. Stress testing against our production workload showed significant increases in latency and a corresponding drop in throughput with more than 32 active concurrent connections. Since we had a lot of excess capacity, so this wasn’t a major concern.
Alternatives
We considered using a method other companies have tried, where the client compresses the JSON before sending data to MySQL. While this reduces load on the databases by moving it to the client, the cost of retrofitting middleware, particularly at the expense of new features, was too high in our case. We needed a solution that didn’t require any changes to the database clients.
We discussed at length modifying MySQL in order to allow compression at the column level. This approach would have different benefits and some tradeoffs:
- We’d realize the maximum disk space savings from compression.
- For pages containing compressed data, we’d only store one copy in memory, so RAM would be used more efficiently than it is with both uncompressed and page-compressed InnoDB.
- For every read we’d need to decompress data, and every write would require a compression operation. This would be especially harmful if we needed to do large sequential scans with many decompression operations.
We were fortunate that Weixiang Zhai from Alibaba had posted a patch for inclusion in Percona Server that implemented this feature. We patched, compiled and tested MySQL using our production workload. The result was similar compression savings to InnoDB page compression (~50%) but with a better performance profile for our workload. This was helpful, but we had another improvement in mind.
Improving column compression
Zlib is the compression library used by InnoDB page compression and the column compression patch from Alibaba. Zlib achieves savings in part by implementing LZ77 and works by replacing occurrences of repeated strings with references to the earlier occurrences. The ability to look back at previous string occurrences would be very useful for page compression but less so for column compression since it’s unlikely field names (among other strings) would occur repeatedly in the same column in a given row.
Zlib version 1.2.7.1 was released in early 2013 and added the ability to use a predefined “dictionary” to prefill the lookback window for LZ77. This seemed promising since we could “warm up” the lookback window with field names and other common strings. We ran a few tests using the Python Zlib librarywith a naive predefined dictionary consisting of an arbitrary Pin JSON blob. The compression savings increased from ~50% to ~66% at what appeared to be relatively little cost.
We worked with Percona to create a specification for column compression with an optional predefined dictionary and then contracted with Percona to build the feature.
Initial testing and a road forward
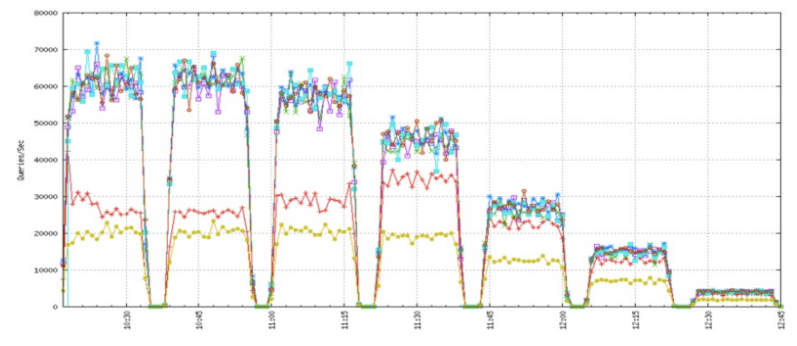
Once an alpha version of column compression was ready, we benchmarked the change and found it produced the expected space savings and doubled throughput at high concurrency. The only downside was large scans (mysqldump, ETL, etc.) took a small performance hit. We presented our findings earlier this year at Percona Live. Below is a graph from our presentation which showed a read-only version of our production workload at concurrency of 256, 128, 32, 16, 8, 4 and 1 clients. TokuDB is in yellow, InnoDB page compression is in red and the other lines are column compression with a variety of dictionaries. Overall, column compression peaked at around twice the throughput on highly concurrent workloads.
In our next post, we’ll discuss how we increased the compression savings using a much less naive compression dictionary.
Acknowledgements: Thanks to Nick Taylor for suggesting the use of predefined dictionary from Zlib, Ernie Souhrada for benchmarking, Weixiang Zhai for writing the original patch and posting it to the Percona mailing list, and Percona for adding in the predefined dictionary feature and being willing to include it in their distribution.