
After some feedback we received from early adopters or discussions during events like FOSDEM, I realized that there is some misconception about the type of replication that MySQL Group Replication is using. And even experts can be confused as Vadim’s blog post illustrated it.
So, is MySQL Group Replication asynchronous or synchronous ??
… in fact it depends !
The short answer is that GR is asynchronous. The confusion here can be explained by the comparison with Galera that claims to be synchronous or virtually synchronous depending where and who claims it (Synchronous multi-master replication library, synchronous replication, scalable synchronous replication solution, enables applications requiring synchronous replication of data, …) . But GR and Galera are not more synchronous than the other.
The more detailed answer is that it depends what do you call “replication”. In fact for years, in the MySQL world, replication defined the process of writing (or changing or deleting) data to a master and the appearance of that data on the slave. The full process is what we called replication. The fact of writing data on a master, adding that change in the binary log, sending it on the relay log of a slave and the slave applying that change… So “replication” is in fact 5 different steps:
- locally applying
- generating a binlog event
- sending the binlog event to the slave(s)
- adding the binlog event on the relay log
- applying the binlog event from the relay log
And indeed, in MySQL Group Replication and in Galera (even if binlog and relay log files are mostly replace by the galera cache), only the step #3 is synchronous… and in fact this step is the streaming of the binlog event (write set) to the slave(s)… the replication of the data to the other nodes.
So yes the process of sending (replicating, streaming) the data to the other nodes is synchronous. But the applying of these changes is still completely asynchronous.
For example if you create a large transaction (which is not recommended neither in InnoDB, Galera and Group Replication) that modifies a huge amount of records, when the transaction is committed, a huge binlog event is created and streamed everywhere. As soon as the other nodes of the cluster/group acknowledge the reception of the binlog event, the node where the transaction was created returns “success” to the client and the data on that particular node is ready. Meanwhile all the other nodes need to process the huge binlog and make all the necessary data modification…. and this can take a lot of time. So yes, if you try to read the data that is part of that huge transaction on another node than the one where the write was done… the data won’t be there immediately. Bigger is the transaction longer you will have to wait for your data to be applied on the slave(s).
Let’s check with some pictures to try to make this more clear, considering the vertical axis is Time, :
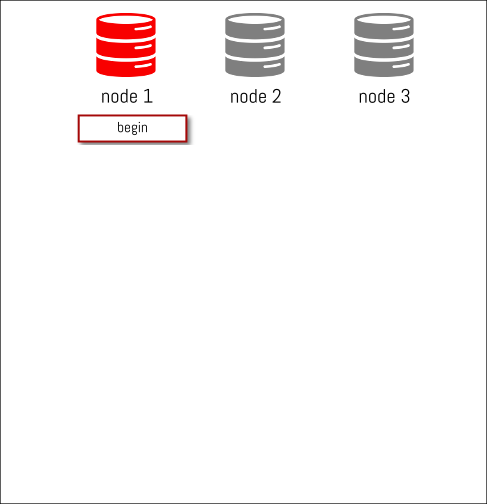
We have a MySQL Group Replication cluster of 3 nodes and we start a transaction on node1
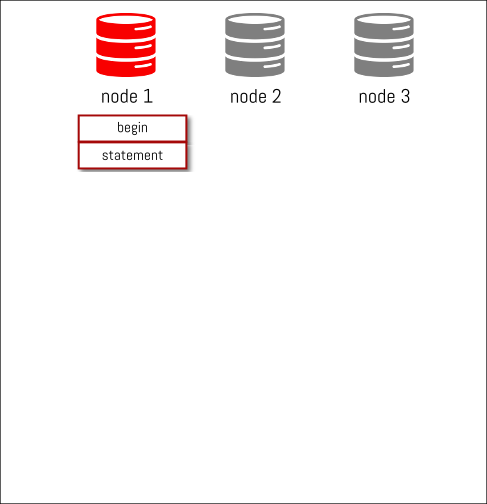
we add some statements to our transaction…
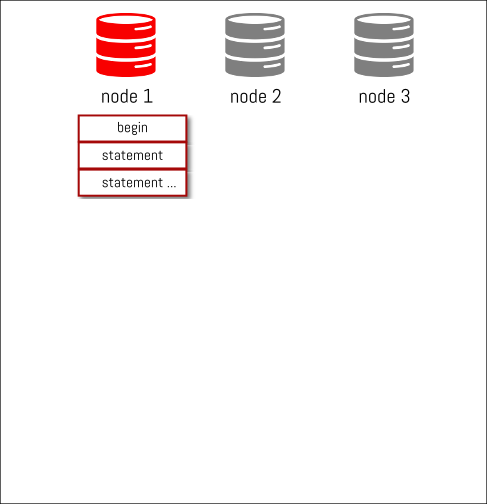
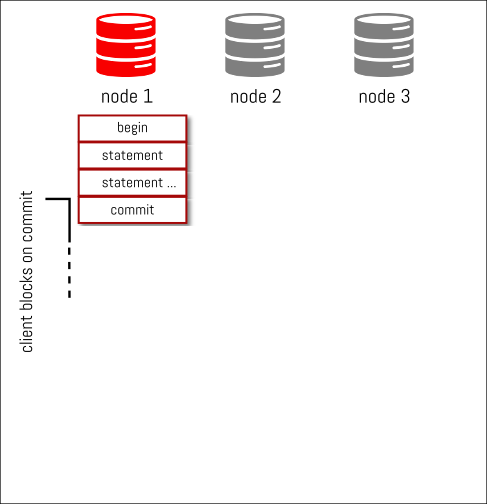
we commit the transaction and binary log events are generated
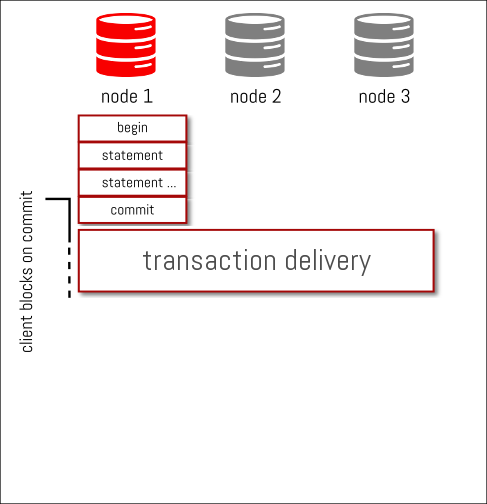
those binlog events are streamed/delivered synchronously to the other nodes and as soon as everybody (*) ack the reception of the binlog events, each node starts certifying them as soon as they can… but independently
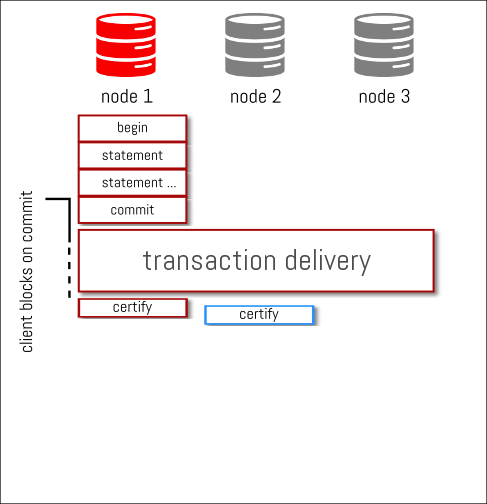
certification can start as son as the transaction is received
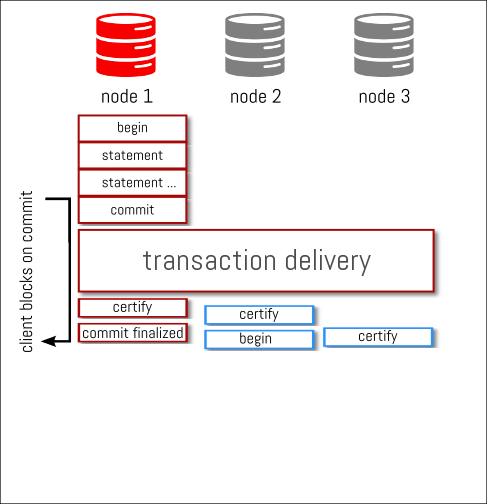
when certification is done, on the writer, there is no need to wait for anything else from the other nodes and the commit result is sent back to the client
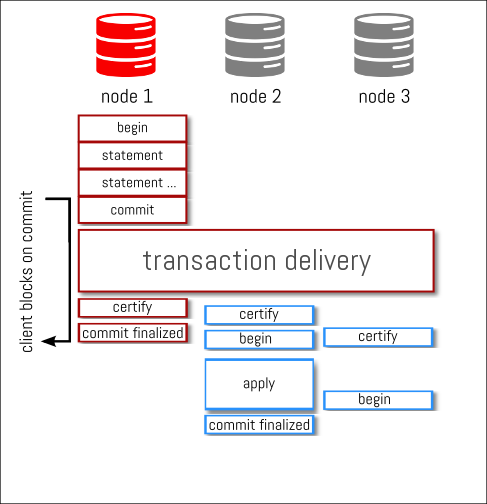
every other nodes consume from the apply queue the changes and start to apply them locally. This is again an asynchronous process like it was for certification
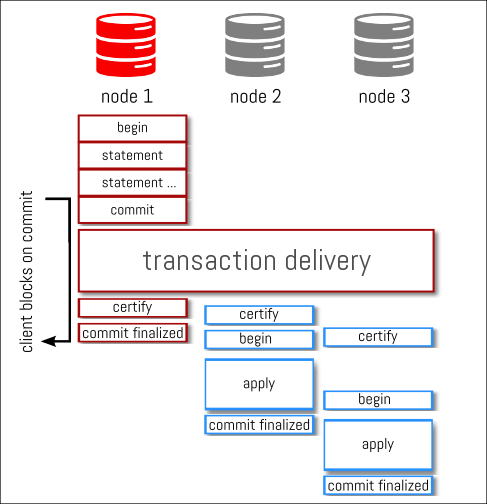
you can see that the transaction is committed on every node at different time
If you perform a lot of large transactions and you want to avoid inconsistent reads, with MySQL Group Replication, you need to wait by yourself and check if there is still some transaction to apply in the queue or verify the last GTID executed to know if the data you modified is present or not where you try to read it. By default this is the same with Galera. However, Galera implemented sync_wait that force the client to wait (until a timeout) for all the transaction in the apply queue to be executed before the current one.
The only synchronous replication solution for the moment is still MySQL Cluster, aka NDB.


