The Web Scraper Chrome extension allows you to scrape websites and extract certain content from them with ease. On the good side, it is easy to use and allows you to completely scrape a website with the option of stopping the scraping process in the middle. In the end, you can save the scraped content in a .csv file which you can easily use to populate a database table.
The official website of the extension is http://webscraper.io/ and you can download it for your Chrome browser from https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn?hl=en
On the bad side, you would have to manually scrape the website each time and cannot programmatically scrape the website on specified intervals.
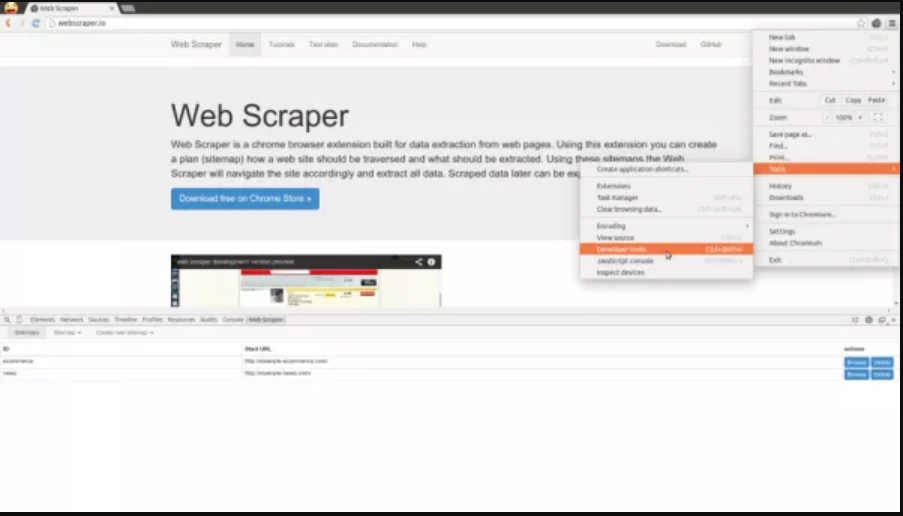
After you install it, you would have to open the Developer Tools (F12 or right click on the page and choose Inspect Element). After you open the Developer Tools, you would find a Web Scraper tab in them as illustrated in the picture below:

Now, we are going to show you how to use it with practical examples.
Let us say we want to scrape http://awesomegifs.com/ and extract the URLs to their gifs. We open the website and see that the images are lazily loaded.
We can see that the real path to the gif image is located in the data-lazy-src attribute and the image is loaded with JavaScript as soon as the user scrolls to it. The img’s src attribute links to a placeholder image that is shown before the real image loads:
Therefore, to capture the content of almost every image on the page (except maybe the first which would already be loaded) we need the following CSS selector: .entry img[data-lazy-src]
Now, we go to the next page to see how pages are formulated and we can see an URL like this: http://awesomegifs.com/page/125/ . To switch between pages we only have to change the page’s number which is currently 125. We play around with the page’s numbers and see that the website contains around 130 pages with gif images. That is why we create a new sitemap, call it awesomegifs and add the following URL in the Start URL field: http://awesomegifs.com/page/[001-125]. This tells Web Scraper to open the URL again and again and increment the final value in the process. Therefore, Web Scraper will open the page http://awesomegifs.com/page/1 the first time and then http://awesomegifs.com/page/2 the second time until it reaches 125.
To switch between pages we only have to change the page’s number which is currently 125. We play around with the page’s numbers and see that the website contains around 130 pages with gif images. That is why we create a new sitemap, call it awesomegifs and add the following URL in the Start URL field:
http://awesomegifs.com/page/[001-125]. This tells Web Scraper to open the URL again and again and increment the final value in the process. Therefore, Web Scraper will open the page http://awesomegifs.com/page/1 the first time and then http://awesomegifs.com/page/2 the second time until it reaches 125.

Each time it opens the page, we want to extract all gifs (all elements matching the CSS selector .entry img[data-lazy-src]. That is why we create a new selector (Sitemaps -> click on our newly created sitemap -> Add new selector) give the selector a unique id of gif, set the type to element attribute (because we want to extract an attribute and not an entire element), check the checkbox Multiple to indicate the element may be present more than once per page, add the selector .entry img[data-lazy-src] and an attribute name of data-lazy-src. The options are shown in the image below:

Finally, we click on the Sitemap tab and choose Scrape to start extracting all gifs from every page on the website:

A popup window like the one in the image below will appear and will start switching between pages and extracting content. Do not close it unless you want to end the scraping process. If you end it prematurely, you will still have the results, just not all of them.



