Write Set is not only in MySQL 8.0 but also in MySQL 5.7 though a little hidden. In this post, I describe Write Set in 5.7 and this will bring us in the inner-working of Group Replication. I am also using this opportunity to explain and show why members of a group can replicate faster than a standard slave. We will also see the impacts, on Group Replication, of the Write Set bug that I presented in my last post.The examples in this post assume that you have a working Group Replication installation (with MySQL 5.7.20 to see the impact of the Write Set bug). I am not describing how to set up Group Replication as Matt Lord already published a good MySQL Group Replication quick start guide that I used myself.
Write Set is used for two things in Group Replication:
- getting faster replication between the members of the group,
- and the certification process for multi-writers.
In this post, I am focusing on faster replication (I will write about the certification process in the next post). So for now, the group does not need to be multi-writers. This means that a member of the group is the primary (where writes are allowed) and all the other members are secondaries.
Group Replication reuses many features of standard MySQL Replication, including LOGICAL_CLOCKparallel replication. This means that its applier can take advantage of parallelism intervals in the relay logs to run transactions in parallel (if you want to know more about parallelism intervals, you can read my post A Metric for Tuning Parallel Replication in MySQL 5.7).
Note that I wrote relay logs (and not binary logs) in the previous paragraph. This is because in Group Replication, the nodes are not replicating using the binary logs: the applier is only using relay logs. This will become clearer with an illustration further in this post; for now, let's look at the relay logs generated by the following commands:
> SELECT version(); +------------+ | version() | +------------+ | 5.7.20-log | +------------+ 1 row in set (0.00 sec) -- On a member of the group that is not the primary, to rotate the relay logs -- of the applier (FLUSH RELAY LOGS does not work with Group Replication): > STOP GROUP_REPLICATION; START GROUP_REPLICATION; Query OK, 0 rows affected (9.10 sec) Query OK, 0 rows affected (3.15 sec) -- All the next commands on the primary member of the group: > SET autocommit = ON; Query OK, 0 rows affected (0.00 sec) > FLUSH BINARY LOGS; Query OK, 0 rows affected (0.00 sec) > CREATE DATABASE test_jfg_ws; Query OK, 1 row affected (0.01 sec) > CREATE TABLE test_jfg_ws.test_jfg_ws ( -> id int(10) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY, -> str varchar(80) NOT NULL UNIQUE); Query OK, 0 rows affected (0.01 sec) > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('a'); Query OK, 1 row affected (0.00 sec) > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('b'); Query OK, 1 row affected (0.00 sec) > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('c'); Query OK, 1 row affected (0.00 sec)
By running the above commands, we get the following in the relay logs of a secondary member of the group. Notice that the parallelism intervals of the three INSERTs are overlapping (comments at the end of the lines added for clarity).
# mysqlbinlog my_relaylog-group_replication_applier.N | grep -e last_ |
sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#180106 19:31:36 [...] last_committed=0 sequence_number=0 [...]
#180106 19:31:36 [...] last_committed=1 sequence_number=2 [...] -- CREATE DB
#180106 19:31:36 [...] last_committed=2 sequence_number=3 [...] -- CREATE TB
#180106 19:31:36 [...] last_committed=3 sequence_number=4 [...] -- INSERT a
#180106 19:31:36 [...] last_committed=3 sequence_number=5 [...] -- INSERT b
#180106 19:31:36 [...] last_committed=3 sequence_number=6 [...] -- INSERT c
As the intervals are overlapping, the three transactions can be run in parallel. However and at least up to MySQL 5.7.20, we do not have overlapping intervals in the binary logs. This means that normal slaves cannot run those transactions in parallel (notice that they were run sequentially on the primary). For the curious (and now you can understand why I ran FLUSH BINARY LOGS above) below is what I get in the binary logs of the primary member of the group (the binary logs of the other members are very similar).
# mysqlbinlog my_binlog.M | grep -e last_ |
sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#180106 19:31:59 [...] last_committed=0 sequence_number=1 [...] -- CREATE DB
#180106 19:32:02 [...] last_committed=1 sequence_number=2 [...] -- CREATE TB
#180106 19:32:05 [...] last_committed=2 sequence_number=3 [...] -- INSERT a
#180106 19:32:08 [...] last_committed=3 sequence_number=4 [...] -- INSERT b
#180106 19:32:11 [...] last_committed=4 sequence_number=5 [...] -- INSERT c
Let's pause and think at this a little more: in Group Replication, the relay logs are getting wider parallelism intervals than the binary logs...
The Group Replication members in MySQL 5.7 can replicate faster than normal slaves because their relay logs contain wider parallelism intervals than the binary logs.
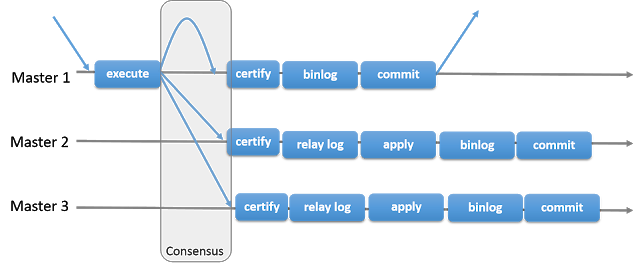
How can this be possible and where does this happen ? Those intervals cannot be generated on the primary as the wider intervals would also reach the binary logs. To understand more, let's look at the image below taken from the manual. This explains how Group Replication executes and commits transactions (and in this image, we can clearly see that "Master 2" and "Master #3" are not replicating from the binary logs of "Master 1" but are still using relay logs).We can now understand/guess that the parallelism interval widening is happening in the certify step of the remote nodes (before writing to the relay logs). This step is using Write Set to detect transaction conflicts (we will come back to that in the next post). At the same time, parallelism interval widening is done, also using Write Set. This allows, if parallel replication is enabled, to run more transactions in parallel on Group Replication members than on normal slaves.
Avoiding lag in Group Replication is what made parallelism interval widening in MySQL 8.0 possible.
However and as I explained in my previous post, Write Set (in MySQL 5.7.20 and 8.0.3) does not identify transaction dependency correctly combined with case insensitive collation (Bug#86078). Let's see how this affects Group Replication by running the following commands:
-- On a secondary member of the group, to rotate the relay logs -- of the applier (FLUSH RELAY LOGS does not work with Group Replication): > STOP GROUP_REPLICATION; START GROUP_REPLICATION; Query OK, 0 rows affected (9.26 sec) Query OK, 0 rows affected (3.16 sec) -- All the next commands on the primary member of the group: > DELETE FROM test_jfg_ws.test_jfg_ws WHERE str = 'c'; Query OK, 1 row affected (0.00 sec) > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('C'); Query OK, 1 row affected (0.00 sec)
By running above, we get the following in the relay logs (notice the overlapping intervals for the DELETE and the INSERT):
# mysqlbinlog my_relaylog-group_replication_applier.N | grep -e last_ |
sed -e 's/server id.*last/[...] last/' -e 's/.rbr_only.*/ [...]/'
#180106 19:36:14 [...] last_committed=0 sequence_number=0 [...]
#180106 19:36:14 [...] last_committed=1 sequence_number=2 [...] -- DELETE c
#180106 19:36:14 [...] last_committed=1 sequence_number=3 [...] -- INSERT C
With the above intervals, the DELETE and the INSERT can be run in parallel which is wrong (Bug#86078): the INSERT depends on the DELETE but Write Set is not identifying this dependency. If the INSERT is run before the row is actually deleted, there will be a duplicate key violation.
Triggering the execution of the INSERT at the same time as the DELETE is not straightforward: the two transactions can only be run sequentially on the primary (the second depends on the first) and they must be run in parallel on the secondary (to trigger the bug). I was able to do that by running a long transaction before the DELETE and INSERT. For that, I created a table with many rows (one million in my case) by running the following commands in a Linux shell on the primary:
# mysql <<< " > CREATE TABLE test_jfg_ws.test_jfg_ws2 ( > id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, > str VARCHAR(80) NOT NULL)" # sql="INSERT INTO test_jfg_ws.test_jfg_ws2 (str) VALUES (RAND());" # for i in $(seq 100); do > ( echo "BEGIN;"; yes "$sql" | head -n 10000; echo "COMMIT;"; ) | mysql > done
With the table above and on my test system, executing the below ALTER takes between three and four seconds (if it takes less than two seconds on your system, add more rows in the table by running the for loop again).
> ALTER TABLE test_jfg_ws.test_jfg_ws2 MODIFY COLUMN str VARCHAR(60); Query OK, 1000000 rows affected (3.57 sec) Records: 1000000 Duplicates: 0 Warnings: 0 > DELETE FROM test_jfg_ws.test_jfg_ws WHERE str = 'C'; Query OK, 1 row affected (0.00 sec) > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('c'); Query OK, 1 row affected (0.00 sec)
By running the DELETE and INSERT just after the ALTER, the two transactions with overlapping intervals are appended to the relay logs while the ALTER is running on the secondary. When the ALTER completes and if parallel replication is enabled, we might trigger Bug#86078 by running the DELETE and the INSERT in parallel.
This also shows that Group Replication is still asynchronous replication: a member can be lagging/delayed.
Let's enable parallel replication and look at the status of the applier on a secondary member of the group:
> STOP GROUP_REPLICATION; Query OK, 0 rows affected (9.83 sec) > SET GLOBAL slave_parallel_type = LOGICAL_CLOCK; Query OK, 0 rows affected (0.00 sec) > SET GLOBAL slave_parallel_workers = 8; Query OK, 0 rows affected (0.00 sec) > START GROUP_REPLICATION; Query OK, 0 rows affected (3.13 sec) > SELECT * FROM performance_schema.replication_applier_status -> WHERE CHANNEL_NAME = 'group_replication_applier'\G *************************** 1. row *************************** CHANNEL_NAME: group_replication_applier SERVICE_STATE: ON REMAINING_DELAY: NULL COUNT_TRANSACTIONS_RETRIES: 0 1 row in set (0.00 sec) > SELECT * FROM performance_schema.replication_applier_status_by_coordinator -> WHERE CHANNEL_NAME = 'group_replication_applier'\G *************************** 1. row *************************** CHANNEL_NAME: group_replication_applier THREAD_ID: 2274 SERVICE_STATE: ON LAST_ERROR_NUMBER: 0 LAST_ERROR_MESSAGE: LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00 1 row in set (0.00 sec)
Then, on the primary, we run the script below in a Linux shell trying to trigger running the INSERT before the DELETE on the remote node where we enabled parallel replication:
# for i in $(seq 10); do > mysql <<< " > SET autocommit = ON; > ALTER TABLE test_jfg_ws.test_jfg_ws2 MODIFY COLUMN str VARCHAR(80); > DELETE FROM test_jfg_ws.test_jfg_ws WHERE str = 'c'; > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('C'); > ALTER TABLE test_jfg_ws.test_jfg_ws2 MODIFY COLUMN str VARCHAR(60); > DELETE FROM test_jfg_ws.test_jfg_ws WHERE str = 'C'; > INSERT INTO test_jfg_ws.test_jfg_ws (str) VALUES ('c');" > done
In above, we might trigger Bug#86078 up to 20 times (the loop is ran 10 times and the race condition happens twice per loop). In my case and by using the first command below, we can see that my test triggered the bug seven times. The second command is getting more information about the last failure.
> SELECT * FROM performance_schema.replication_applier_status -> WHERE CHANNEL_NAME = 'group_replication_applier'\G *************************** 1. row *************************** CHANNEL_NAME: group_replication_applier SERVICE_STATE: ON REMAINING_DELAY: NULL COUNT_TRANSACTIONS_RETRIES: 7 1 row in set (0.00 sec) > SELECT * FROM performance_schema.replication_applier_status_by_coordinator -> WHERE CHANNEL_NAME = 'group_replication_applier'\G *************************** 1. row *************************** CHANNEL_NAME: group_replication_applier THREAD_ID: 2274 SERVICE_STATE: ON LAST_ERROR_NUMBER: 1062 LAST_ERROR_MESSAGE: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 2 failed executing transaction 'UUID:177' at master log , end_log_pos 168. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any. LAST_ERROR_TIMESTAMP: 2018-01-06 19:42:33 1 row in set (0.00 sec)
I also get the below seven lines in the error log (line wrapping added for easier reading):
2018-01-06T18:41:23.331363Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:126' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'C' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062 2018-01-06T18:41:31.885927Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:132' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'C' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062 2018-01-06T18:41:52.143778Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:147' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'c' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062 2018-01-06T18:41:56.857187Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:150' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'C' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062 2018-01-06T18:42:05.385074Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:156' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'C' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062 2018-01-06T18:42:25.254811Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:171' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'c' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062 2018-01-06T18:42:33.694658Z 2242 [ERROR] Slave SQL for channel 'group_replication_applier': Worker 2 failed executing transaction 'UUID:177' at master log , end_log_pos 168; Could not execute Write_rows event on table test_jfg_ws.test_jfg_ws; Duplicate entry 'c' for key 'str', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log FIRST, end_log_pos 168, Error_code: 1062
To trace the impact of Bug#86078 on Group Replication, I opened Bug#89141: Error in Group Replication caused by bad Write Set tracking.
Also, and I will not discuss those in more detail here, my tests on Group Replication allowed to find a few behaviors that I think should be improved or that I consider wrong. So I opened the following bugs/feature requests:
- Bug#89142: Make FLUSH RELAY LOGS work for Group Replication.
- Bug#89143: Standard and Group Replication behave differently on slave_transaction_retries.
- Bug#89145: Provide relay log details in case of Group Replication applier failure.
- Bug#89146: Word missing in Group Replication error messages.
- Bug#89147: The field end_log_pos in GR error messages is ambiguous.
- Bug#89148: The timestamp of the GITD events in the GR relay logs look wrong.
Those bugs are all relatively minors. However, I found a more concerning impact of Bug#86078 (Bad Write Set tracking with case insensitive collation). This will be the subject of the next post where I will dive in the certification process of Group Replication. Update, this post has been published: More Write Set in MySQL: Group Replication Certification.
I hope you enjoyed reading this post and that it allowed you to understand many things, including how a member of Group Replication can replicate faster than a standard slave (we somehow diverged a little to other things though). As a summary:
- Group Replication can replicate faster than normal slaves (in MySQL 5.7.20) because their relay logs contain wider parallelism intervals than the binary logs,
- Those wider intervals are generated during the certification process by using the Write Set data structure,
- Those wider intervals can be used by a multi-threaded applier (LOGICAL_CLOCK) for running transactions in parallel,
- The Group Replication applier can lag (asynchronous replication),
- And the MySQL 8.0 improvement on standard parallel replication (wider intervals thanks to Write Set described in the previous post) is a direct application of Group Replication work.