If you’re working with big data and Hadoop, this one paper could repay your investment in The Morning Paper many times over (ok, The Morning Paper is free – but you do pay with your time to read it). You know that moment when you’re working on a code base and someone says “why don’t we replace all this complex home-grown code and infrastructure with this pre-existing solution…?” That!
Here’s the big idea – for large HDFS installations, the single node in-memory metadata service is the bottleneck. So why not replace the implementation with a NewSQL database and spread the load across multiple nodes? In this instance, MySQL Cluster was used, but that’s pluggable. Of course, there will be some important design issues to address, but the authors do a neat job of solving these. I especially like that the paper is grounded in real world workloads from Spotify (and we get some nice insights into the scale of data at Spotify too as a bonus).
All very nice, but what difference does HopFS (a drop-in replacement) make in the real world? How about:
- Enabling an order-of-magnitude larger clusters
- Improving cluster throughput by an order-of-magnitude (16x – 37x)
- Lower latency when using large numbers of concurrent clients
- No downtime during failover
Think of the capital and operational costs of having to stand up a second large-scale Hadoop cluster because your existing one is capacity or throughput limited. HopFS is a huge win if it eliminates your need to do that.
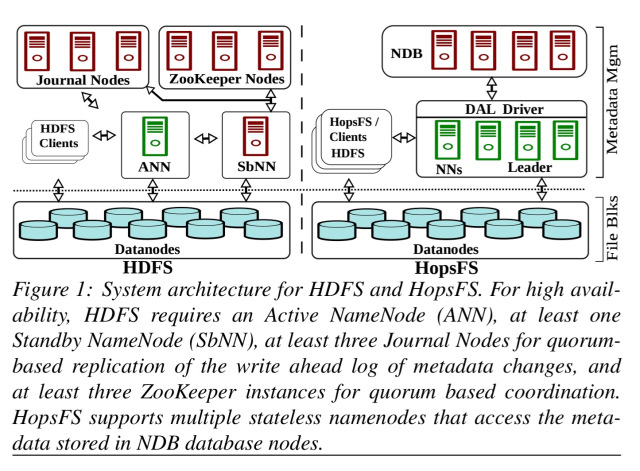
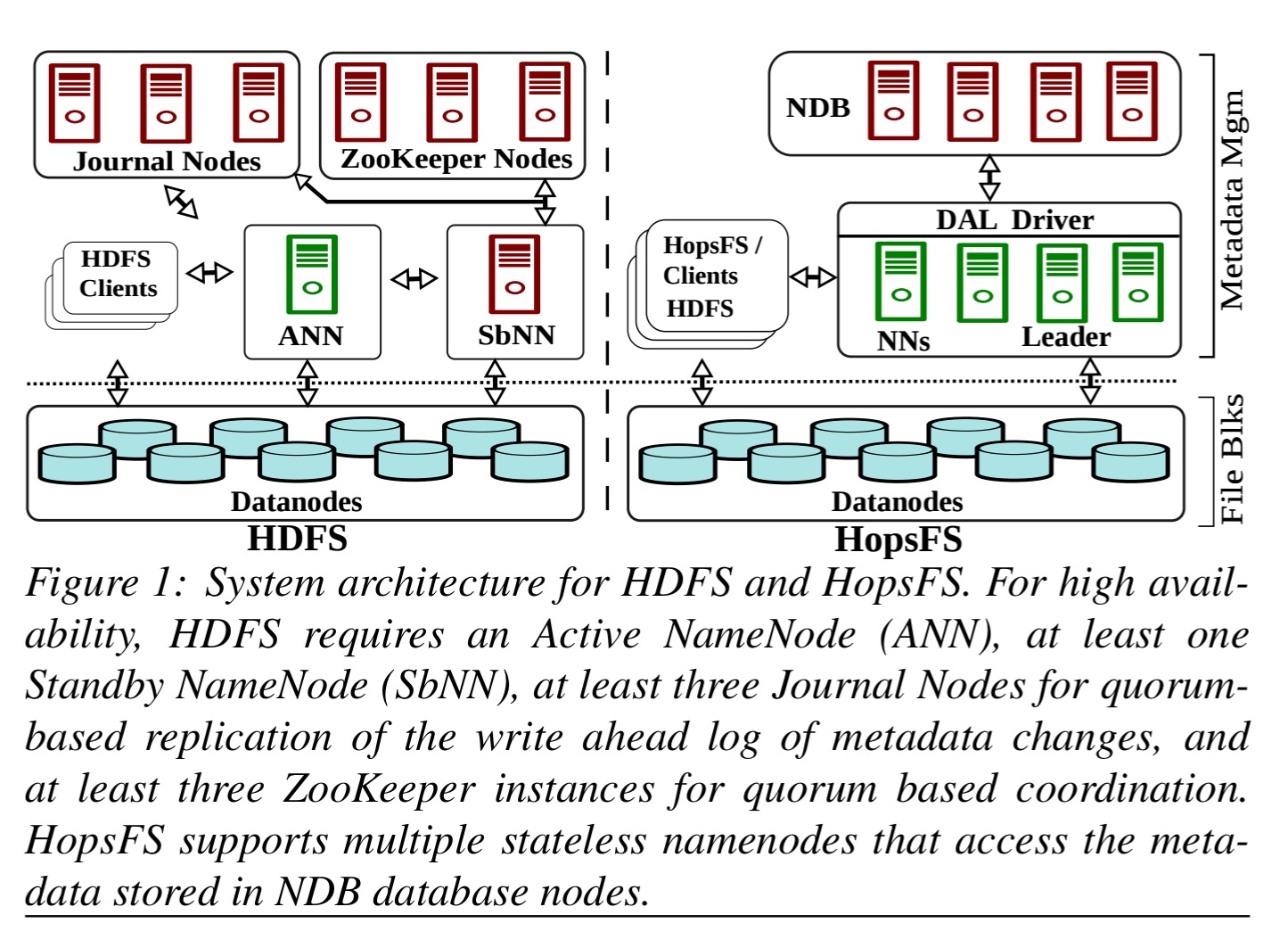
NameNodes in Apache Hadoop vs HopFS
In vanilla Apache Hadoop, HDFS metadata is stored on the heap of a single Java process, the Active NameNode (ANN). The ANN logs changes to journal servers using quorum based replication. The change log is asynchronously replicated to a Standby NameNode. ZooKeeper is used to determine which node is active, and to coordinate failover from the active to the standby namenode. Datanodes connect to both active and standby namenodes.
In HDFS the amount of metadata is quite low relative to file data. There is approximately 1 gigabyte of metadata for every petabyte of file system data. Spotify’s HDFS cluster has 1600+ nodes, storing 60 petabytes of data, but its metadata fits in 140 gigabytes Java Virtual Machine (JVM) heap. The extra heap space is taken by temporary objects, RPC request queues and secondary metadata required for the maintenance of the file system. However, current trends are towards even larger HDFS clusters (Facebook has HDFS clusters with more than 100 petabytes of data), but current JVM garbage collection technology does not permit very large heap sizes, as the application pauses caused by the JVM garbage collector affects the operations of HDFS. As such, JVM garbage collection technology and the monolithic architecture of the HDFS namenode are now the scalability bottlenecks for Hadoop.
HopFS is a drop-in replacement for HDFS, based on HDFS v2.0.4. Instead of a single in-memory process, it provides a scale-out metadata service. Multiple stateless namenode processes handle client requests and store data in an external distributed database, MySQL Cluster. References to NDB throughout the paper refer to the Network DataBase storage engine for MySQL Cluster.
Partitioning
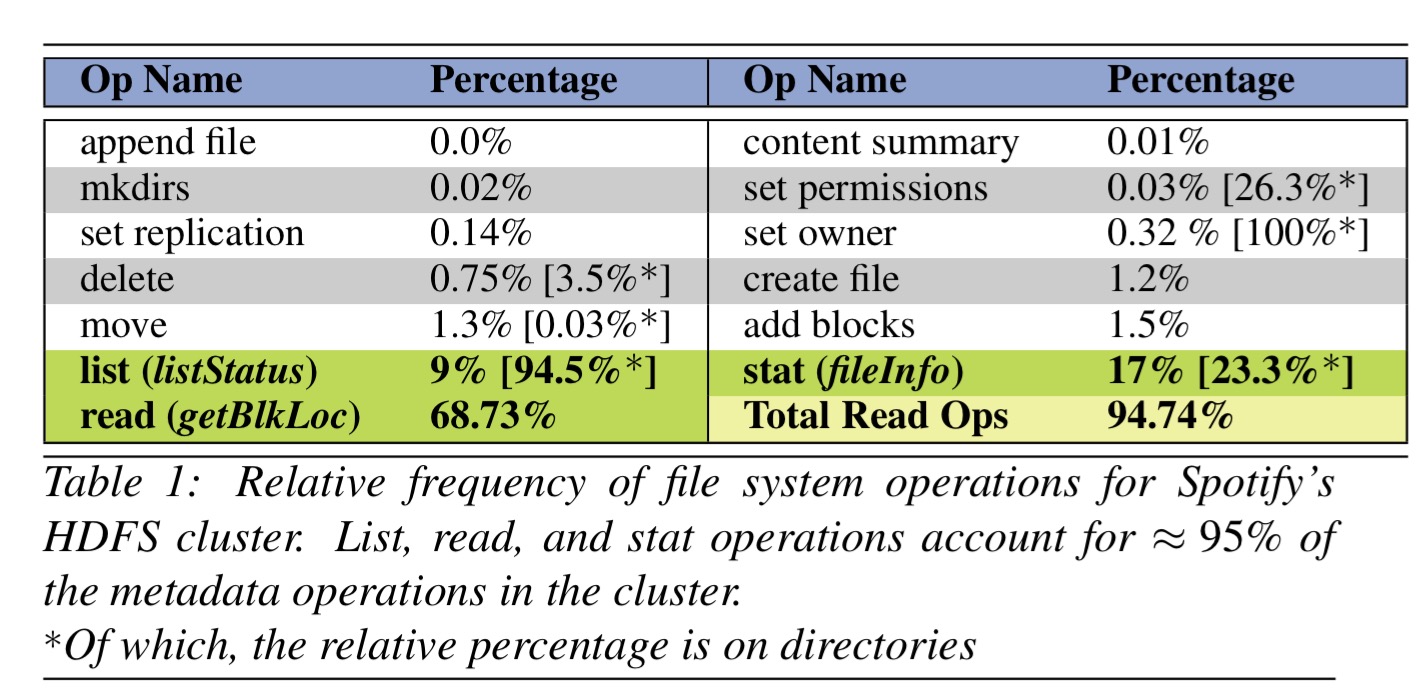
HDFS metadata contains information on inodes, blocks, replicas, quotas, leases and mappings (dirs to files, files to blocks, blocks to replicas).
When metadata is distributed, an application defined partitioning scheme is needed to shard the metadata and a consensus protocol is required to ensure metadata integrity for operations that cross shards.
The chosen partition scheme is based on a study of the relative frequency of operations in production deployments. Common file system operations (primary key, batched primary key, and partition pruned index scans) can be implemented using only low cost database operations.
File system metadata is stored in tables, with a directory inode represented by a single row in the Inode table. File inodes have more associated metadata, that is stored in a collected of related tables.
With the exception of hotspots, HopFS partitions inodes by their parents’ inode IDs, resulting in inodes with the same parent inode being stored on the same database shard.
A hinting mechanism allows e.g., the transaction for listing files in a directory to be initiated on a transaction coordinator on the shard holding the child inodes for the directory.
Hotspots are simply inodes that receive a high proportion of file system operations. The root inode is immutable and cached at all namenodes. The immediate children of top level directories receive special treatment to avoid them becoming hotspots – they are pseudo-randomly partitioned by hashing the names of the children. By default just the first two levels of the hierarchy receive this treatment.
Transactions
HopFS uses transactions for all operations, coupled with row-level locking to serialize conflicting inode operations. Taking multiple locks in a transaction can lead to deadlocks and timeouts unless care is take to avoid cycles and upgrade deadlocks.
To avoid cycle deadlocks, HopFS reimplemented all inode operations to acquire locks on the metadata in the same total order. (Root to leaves, left-ordered depth-first search). Upgrade deadlocks are prevented by acquiring all locks at the start of the transaction.
In HDFS, many inode operations contain read operations followed by write operations on the same metadata. When translated into database operations within the same transaction, this results in deadlocking due to lock upgrades from read to exclusive locks. We have examined all locks acquired by the inode operations, and re-implemented them so that all data needed in a transaction is read only once at the start of the transaction at the strongest lock level that could be needed during the transaction, thus preventing lock upgrades.
Inode operations proceed in three phases: lock, execute, and update.

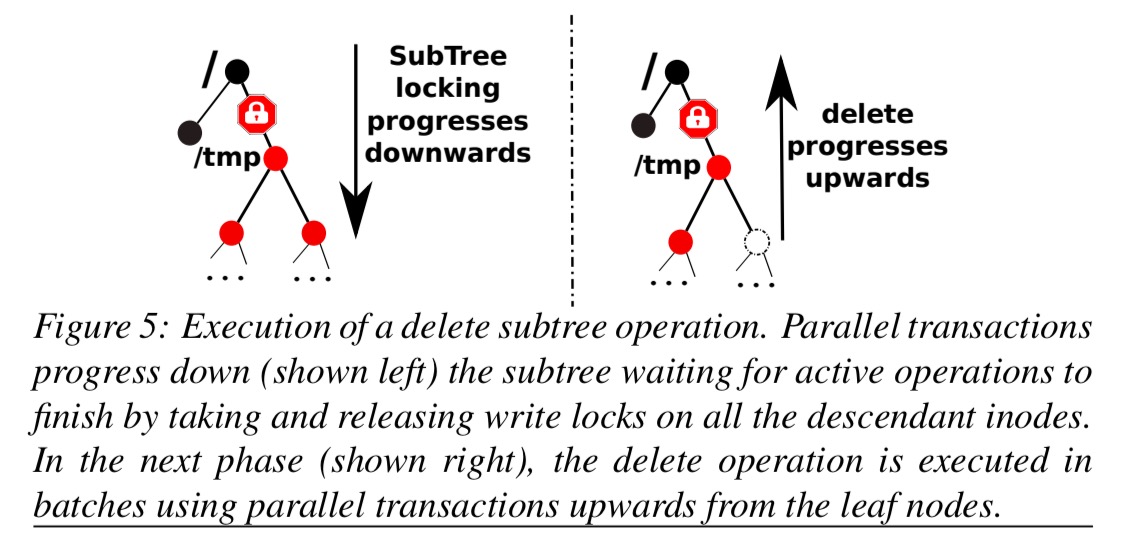
Operations on large directories (e.g, containing millions of inodes) are too large to fit in a single transaction. A subtree operations protocol instead performs such operations incrementally in a series of transactions.
We serialize subtree operations by ensuring that all ongoing inode and subtree operations in a subtree complete before a newly requested subtree operation is executed. We implement this serialization property by enforcing the following invariants: (1) no new operations access the subtree until the operation completes, (2) the subtree is quiesced before the subtree operation starts, (3) no orphaned inodes or inconsistencies arise if failures occur.
Evaluation
For the evaluation, HopFS used NDB v7.5.3 deployed on 12 nodes configured to run 22 threads each, and with data replication degree 2. HDFS namenode suport was deployed on 5 servers: one active namenode, one standby namenode, and three journal nodes colocated with three ZooKeeper nodes. The benchmark used traces from Spotify’s 1600+ node cluster containing 60 Petabytes of data, 13 million directories, and 218 million files. This cluster runs on average 40,000 jobs a day from a variety of applications.
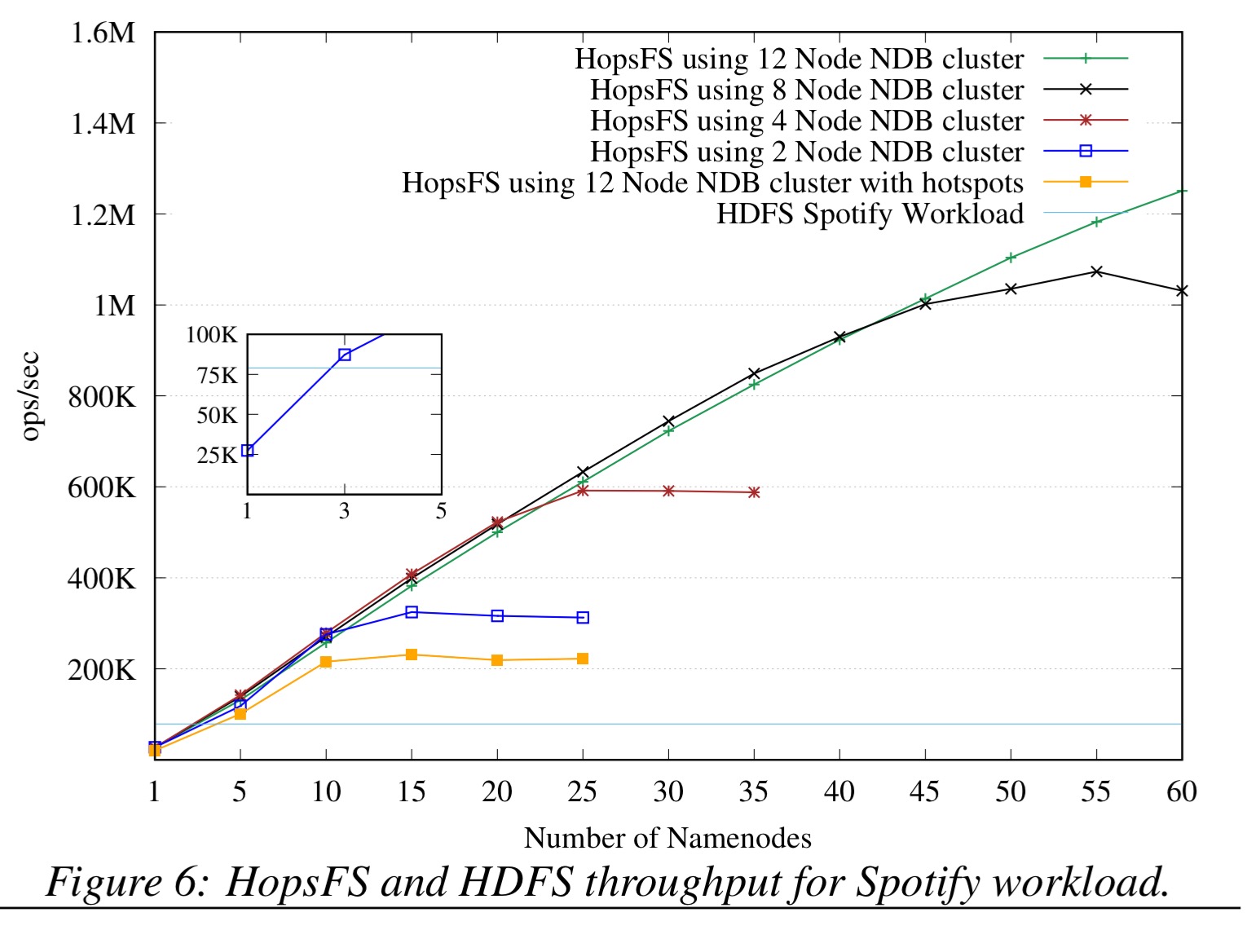
Figure 6 (below) shows that, for our industrial workload, using 60 namenodes and 12 NDB nodes, HopsFS can perform 1.25 million operations per second delivering 16 times the throughput of HDFS. As discussed before in medium to large Hadoop clusters 5 to 8 servers are required to provide high availability for HDFS. With equivalent hardware (2 NDB nodes and 3 namenodes), HopsFS delivers ≈10% higher throughput than HDFS. HopsFS performance increases linearly as more namenodes nodes are added to the system
HDFS reaches a file limit of about 470 million files due to constraints on the JVM heap size. HopFS needs about 1.5 times more memory in aggregate than HDFS to store metadata that is highly available, but it can scale to many more files…

A saturation test explored the maximum throughput and scalability of each file system operation. “In real deployments, the namenode often receives a deluge of the same file system operation type, for example, a big job that reads large amounts of data will generate a huge number of requests to read files and list directories.”
In the results below, HopFS’ results are displayed as a bar chart of stacked rectangles, each representing the increase in throughput when five new namenodes are added:
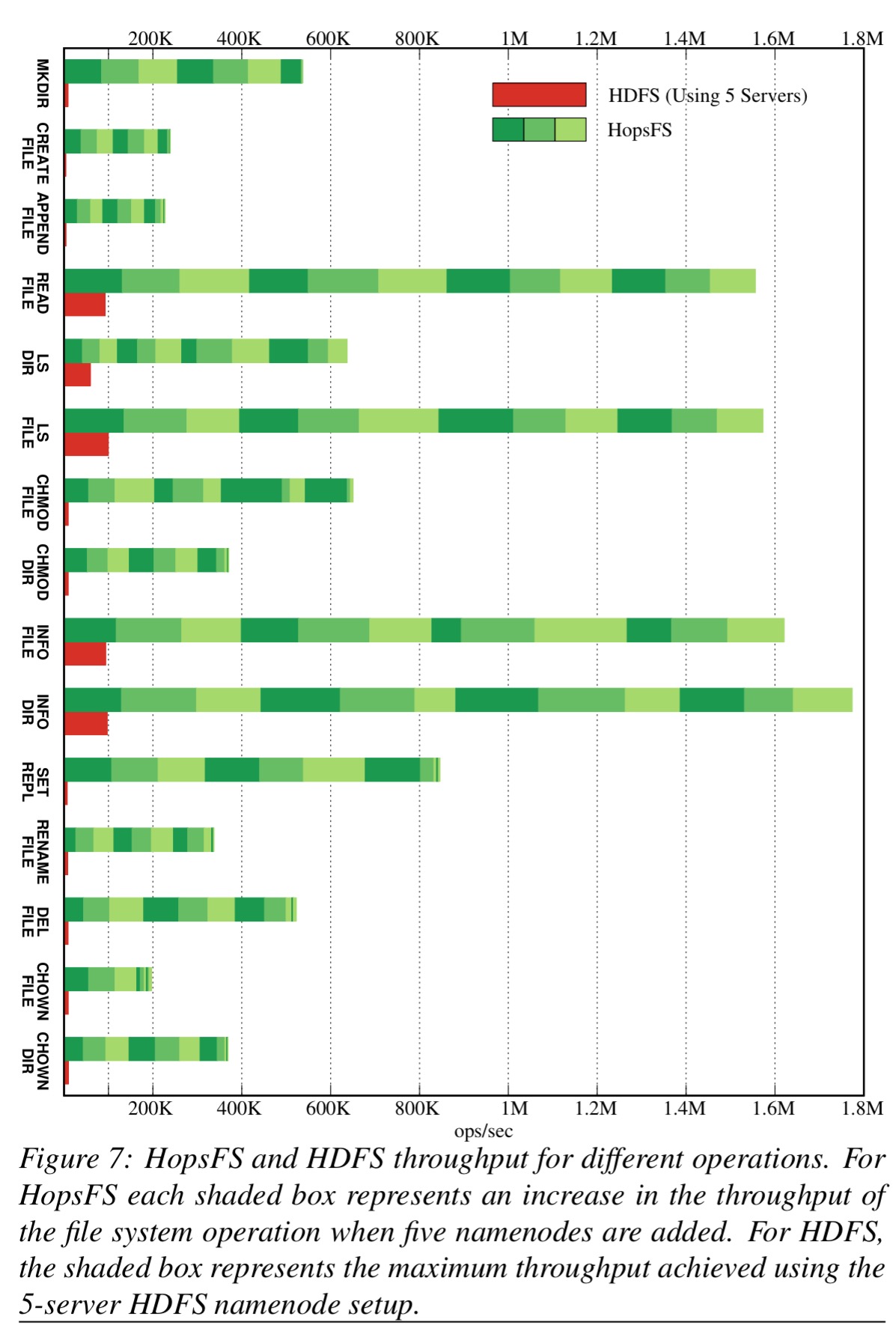
HopFS outperforms HDFS for all file system operations and has significantly better performance than HDFS for the most common file system operations.
When it comes to latency, it is true that HopFS is slower than HDFS for single filesystem operations on unloaded namenodes. But start to scale up the workload and you can quickly see HopFS has the advantage:

Large HDFS deployments may have tens of thousands of clients and the end-to-end latency observed by the clients increases as the file system operations wait in RPC call queues at the namenode. In contrast, HopFS can handle more concurrent clients while keeping operation latencies low.
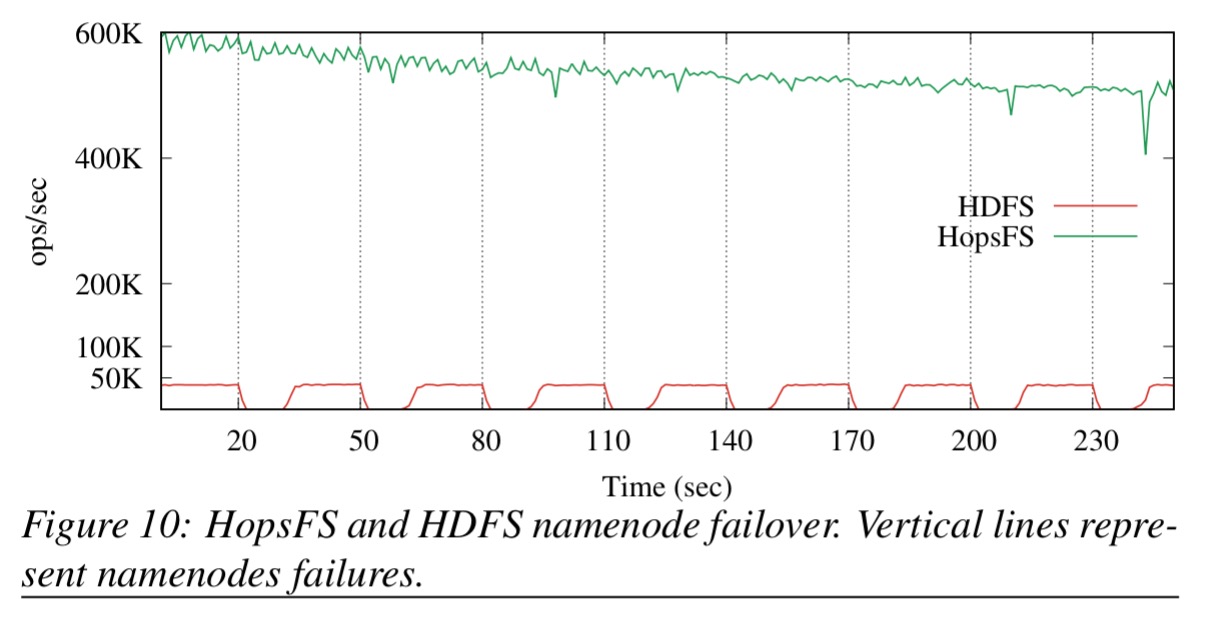
HopFS provides much faster failover with no downtime too:
Surely there is some downside to HopFS?? Well, yes there is one: HopFS can only process about 30 block reports a second, whereas HDFS does 60. But HopFS doesn’t need block reports as often as HDFS does, and with datanodes sending block reports every six hours it can still scale to exabyte sized clusters.
The bottom line:
HopsFS is an open-source, highly available file system that scales out in both capacity and throughput by adding new namenodes and database nodes. HopsFS can store 37 times more metadata than HDFS and for a workload from Spotify HopsFS scales to handle 16 times the throughput of HDFS. HopsFS also has lower average latency for large number of concurrent clients, and no downtime during failover. Our architecture supports a pluggable database storage engine, and other NewSQL databases could be used.