Pinterest’s main data source–Pin data–is stored as medium-sized (~1.2kb) JSON blobs in our MySQL cluster. These blobs are very compressible, but the existing compression system in MySQL was less than optimal and only resulted in 2:1 compression. In a previous post, we discussed why column compression is a more ideal compression system. In order to use column compression and have significant savings, we need to use a compression and optional predefined compression dictionary (i.e. lookback window). Here we’ll cover how we increased the compression ratio of Pin data from around 3:1 to 3.47:1.
Background
First, let’s take a look at the underlying compression library used by InnoDB, Zlib, a compression library initially used for the PNG file format. Zlib’s compression follows the DEFLATE compression algorithm which consists of two main stages. First, LZ77 replaces recurring strings with a pointer to a previous instance of that string as well as the length of the string to repeat. Then the resulting data is Huffman encoded. We optimize the LZ77 stage by using a predefined dictionary that preloads the lookback window with common substrings. This works especially well since each data object compressed is much smaller than the sliding window, allowing the entirety of each Pin object to look back into the majority of the predefined window. We were inspired by similar work done by Cloudflare.
Initial tests
Before starting this project, the predefined dictionary was populated with a single Pin object. The compression ratio was roughly 3:1, which is good given all Pin objects share roughly the same scheme, allowing keys to be reused. However, we knew we could do better.
It’s common for Pins to share certain JSON fields or substrings of those fields. By using only a single Pin, we weren’t taking advantage of additional savings accessible through those JSON values. Examples of such fields are links which often start with “http://” or fields expecting boolean values. I ran a few quick compressions to ensure there were savings to be had. I took roughly 10,000 Pins, concatenated them and compressed them using the largest window size (32kb) and highest compression level (Z_BEST_COMPRESSION, 9). This allowed each Pin to look back into the previous 25 or so Pins for common strings while compressing the data as much as possible. I then did the same thing, but, shuffled the bytes of each Pin before concatenating. Because the relative frequency of each byte is still the same (disregarding strings that are replaced with the LZ77 lookback tuple), the Huffman encoding portion of DEFLATE yielded roughly the same savings. The difference in compression ratios would provide an approximation of expected savings. Another option was to populate the predefined dictionary with a handful of Pins using deflateSetDictionary, but the first method allowed roughly the same outcome without having to write code. Regardless, the results showed there were savings to be had, so I continued on with the project.
The process
Initially, I tried modifying the Zlib source to determine which common strings the LZ77 portion compressed for use in the pre-defined dictionary. Programming in C isn’t my fastest coding language, so after a week or so I decided it’d be less painful to write to write my own utilities to generate a decent pre-defined dictionary for Pin objects than to spend my internship trying to become proficient with highly optimized K&R style C.
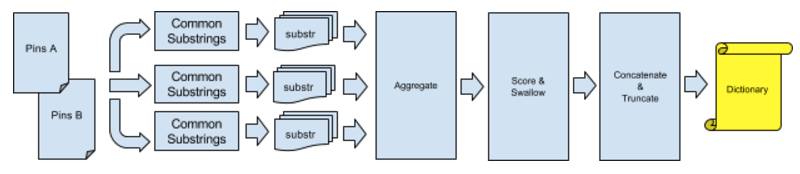
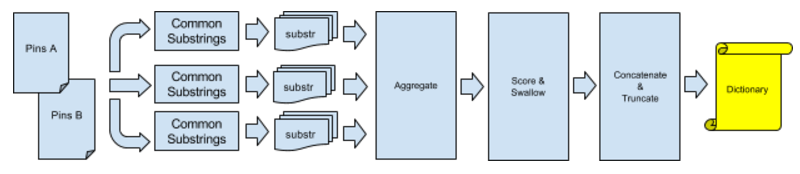
I took a large number of Pins (~200k) from two different shard DBs and two different generation eras. We shard based on userID, so earlier shard DBs contain a lot of older Pins with somewhat different schemas than more recently added Pins.
In order to generate a more general pre-defined dictionary for all generations of Pins, I shuffled the input data in three different ways:
- Random Pin pairs from the older shard.
- Random Pin pairs from the newer shard.
- Random Pins from the older shard paired with random Pins from the newer shard.
I then batched the Pin pairs and concurrently looked for common substrings (within the lookback window and lookahead buffer, all larger than 3 bytes) between each Pin pair in the batch.
Because this is a long running process, I maintained persistent state at the end of each completed batch which allowed the script to start from the last completed batch in the event of failure. The substring frequencies from each batch were then aggregated and passed onto the next step, dictionary generation.
Dictionary generation
After batching, the substring are scored based on the length of substring and the occurring frequency. In order to avoid repeating substrings in the output dictionary, we swallow fully contained substrings and incorporate the score into the swallowing substring’s score. The highest n scoring strings that fit in the defined dictionary size are concatenated such that higher scoring strings are at the end of the dictionary (as per the zlib manual). Then, any overhang is truncated and the results are handed to the user as the pre-defined dictionary.
Although the implementation was slow, we found the frequencies of common substrings between 100,000 pairs of Pins in slightly more than 400 CPU days. We didn’t devote time to improving performance, because generating the dictionary itself isn’t a frequently run task. Furthermore, as much as I would’ve liked to come up with an efficient shortest common supersequence solution to fit more in the pre-defined dictionary, it’s NP-complete.
These tools have been added to our open source tools repository in the hope they might be useful to others.
Benchmarks
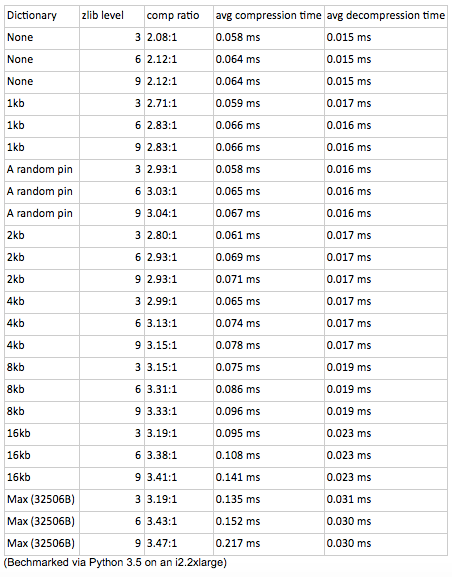
Benchmarks using this predefined dictionary looked promising. In terms of space savings, the computed dictionary saves more than 10 percent versus using a single Pin as the predefined dictionary, in addition to 40 percent savings over the existing InnoDB Page Compression. We considered using an 8kb or 16KB dictionary over a ~32KB (32506B) dictionary as a tradeoff to increase performance, but since it wasn’t a requirement, we didn’t increase the zlib compression level to maximize the compression savings.
Next steps
When the first blog post on column compression was written, we hadn’t deployed this change to production. Since, we’ve pushed column compression out without incident.
In the future, we’re planning to test a Pin-curated static Huffman tree as a potential pathway to additional savings. Currently, zlib doesn’t support this functionality and will either use a general static code or a dynamic code, depending on size.
Acknowledgements: Thanks to Rob Wultsch for his guidance and mentorship. Thanks to Pinterest for making my internship a memorable experience.